
最强的32B中国推理模型! DeepSeek
栏目:企业动态 发布时间:2025-04-16 19:41
对1000亿参数的最强理解模型仅易手。 32B - 卷1/20 deepSeek-r1参数;免费商业用途;...
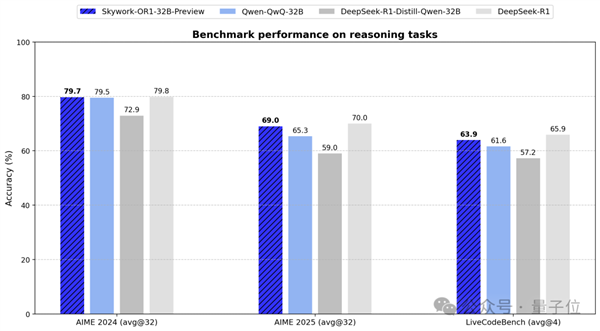 对1000亿参数的最强理解模型仅易手。 32B-卷1/20 Deviceek -R1参数;免费商业用途;完全打开源 - 型号的权重,训练集和完整的培训代码,所有开放式起源。这是刚刚发布的Skywork-Or1(开放式推理1)系列模型 - 一般32B尺寸(SkyWork-O1-32B)完全比相同尺寸的Alibaba QWQ-32B多;代码的产生与DeepSeek-R1相当,但成本效益更高。 △SkyWork-OR1-32B-Preiview数学推理:7B和32B都达到了最佳尺寸,而数学专家模型(Skywork-Or1-Math-7B)的性能更为致命。天冈的天空制品也来自AIGC巨头球员Kunlun Wanwei。 Skywork-O1系列模型是完全开放的资源,具有重量的权重,培训数据集和完整的培训代码,所有资源都将上传到GitHub和HuggingFace平台。技术支持博客有蜜蜂n发表在概念平台上,该平台详细说明了数据处理过程,培训方法和基本技术发现,为社区提供了完全实用的实用参考。 The Skywork-Or1 Series Open Source Address: https://github.com/skyworai/skywork-or1 (including models, code, data) Kunlun Wanwei Tiangong Team is more open project resources: https://huggingface.co/Skywork at present, Skywork-or1-7B and Skywork-OR1-32b capabilities are capabilities Still improving.这两个模型的官方版本将在两周内发布,并将启动更多系统和详细的技术报告,以在理解的培训模型中分享经验和PEXERCISE。 3型模型是Skywork-Or1的完全开放资源(开放推理1)开放资源系列中有3种型号:Skywork-Or1-Math-7B:一种专门用于数学领域的特殊模型,并且也有强大的代码功能。 Skywork-O1-7B变化:结合数学考虑到一般和专业精神,及格和代码功能。 Skywork-Or1-32b-Preiview:具有高复杂和更强推理功能的任务的旗舰版本。该团队将Skywork-O1系列的性能与AIE24,AIME25和LiveCodebench进行了比较。 AIE24/25是美国数学邀请赛的基准测试,LiveCodeBench主要评估大语言模型的代码和编程功能的生成。在审查方面,SkyWork-O1系列模型在AVG@K中引入了基本分析的指标,以衡量模型的平均性能,这些模型的平均性能在与K进行尝试时成功解决问题的平均性能仅关注“较少成功”的“对模型的稳定性”,并且更关心模型的稳定性和一般的推理能力,从而提供了一个更全面的模型,并实现了实施模型的实现,从而实现了实现的实现。 Skywork-or1-7b-preiview和Skywork-O1-32b-previews在AIME24和AIME25数据集中的相同参数量表下都达到了最佳性能。 Skywork-O1-32b-preiviews都在LiveCodeBench的LiveCodeBench中实现了最佳功能。通常,Skywork-Or1-32b-preview和DeepSeek-R1之间的差距很小。重要的是要知道,后者的参数量表是前者的20次,这意味着SkyWork-OR1可以带来更好的性能成本。从这个全面的角度来看,SkyWork-O1-32B-Preiview已成为中国对相同规模的认识的最强模型,也是当前支持免费商业用途的当前模型中最强大,最有效的成员之一。此外,Skywork-O1-Math-7b的数学特殊模型是E24/25性能的目标,超出了主7B的当前模型,甚至与Distiled DeepSeek-32B型号(DeepSeek-R1-Disti-Disti-Disti-disti-disti-qwen-32b)接近相同的水平。以下是准确性的曲线AIE24中的模型培训。在AIE24和AIME25中,最终模型分别超过了OpenAi-O3-Mini(低),该模型分别达到了当前SOTA性能大小。同时,这种特殊模型在代码领域也表现出极大的暴力行为(训练后,LiveCodebench从37.6%增加到43.6%)。 △去年11月11月,openai-o3-Mini(低)AIME24标记来自官方网站,Aime25 Mark来自评论网站https://matharen.ai/in,Kunlun Wanwei发布了第一个在中国更复杂的中国模型,在中国,SkyWork-O1,Skywork-Or1系列模型。与OpenAI O1型号的简单复制品不同,Skywork-O1具有内源性功能,例如思考,计划和反思。它包括三种型号,Skywork-O1,Skywork-O1,Kywork-O1-Lite和SkyWork-O1-previews适合各种应用程序,并且可以满足高性能推理中开放资源的不同需求。这Skywork-O1系列在Skywork-O1肩上具有更强的基础,但希望非常强大。它也不能与一系列高级技术的祝福分开。其背后的秘密是:AGI技术有隐藏的漏洞,训练效率提高了50%。 Skywork-O1已进行了其他数据处理更改,培训技术等。首先,就数据而言。为了提高数学功能和模型代码,SkyWork-O1构建了高质量的数学和代码数据集。该团队设计了三个用于数据过滤的标准:经过证实,正确和具有挑战性的和删除的证明问题,这些问题无法自动验证,错误的问题和代码问题,以使单位测试进行。在数学领域总共收集了110,000个问题,主要依靠Numinamath-1.5(包括约896,000个问题),选择了更困难的子集,例如Aime和OlympiaDs,以及诸如DeepScaler,Omni之类的困难问题的资源-Math和Aime 1983-2023增加了。代码字段收集了13.7k,主要基于Leetcode和Taco数据,从而维持完整的测试单元和验证问题,以及向量级别的语义扣除。在“数据过滤器”部分中,团队为每个问题进行了大量抽样,并经过证实的答案,以避免“正确”或“所有错误”的奇观,这些奇观无效,而战略研究无效 - 该模型会产生所有错误,并且无法提供阶层的研究信号; “继续”意味着该模型已完全掌握,并且不断学习的人将浪费计算资源。通过人类的受众群体结合了LLM自动判断的机制,清除了具有模糊语义,不完整信息,不正确格式或包含无关内容的项目。使用LLM-AS-A-Gudge消除1-2K质量失败的数学问题。第二,在强化研究的一部分中,SkyWork-or1使用TRAI的GRPO(相对策略优化)Ning并引入一系列优化技术。在训练过程中,一方面采用了双滤波器方法:离线滤波:使用模型在训练前评估数据,并以0或1的准确率删除样品;在线过滤:每个时期都是在上一个周期中完全掌握的数据的动态删除,以确保模型不断面临着具有挑战性的内容。另一方面,拒绝下降用于进行固定的实时筛选,并且在每个练习步骤中,在当前训练步骤中采样精度为0或1的样品被动态删除。它可以维持政策损失,熵损失和KL损失的合理比率,并防止由于特定重力的非政策损失异常增加而导致的训练不稳定。探索的两个方面主要是在训练管道中进行的。 (1)在多个阶段进行练习:从一个小窗口开始ly增加上下文长度(SEQ_LEN),可以在有限的令牌内促使模型完成活动;然后逐渐扩大窗口大小,并迭代地增加一代的长度,以便模型可以逐步掌握更复杂的长链思维功能。实验证明,多阶段训练可以大大缩短训练时间,同时充分维护模型长度扩展的能力。 。因此,团队研究了两种技术,用于在窗户处理限制下截断样品。 adv-mask之前(在计算优势之前排除截短的样本)和adv-bask(随后添加了Adv-bask)(在计算后与截短样品的好处进行零)。这证明,即使在不阻止截短的样本的情况下,该模型也可以有效地适应并迅速提高性能,并且还证明了多阶段训练框架的稳定性。此外,该模型的勘探能力应保证TICE加强培训。团队进行了探索的三个方面。首先,高温采样。使用τ= 1.0(高于通常的0.6)保持较高的组,这不仅确保足够正确的示例提供研究信号,而且还允许该模型探索更大的解决方案。其次,改善差异 - 内部训练是不同的。通过精细的数据过滤,增加批处理大小并减少数据重复使用,我们将避免从资源的输出方向朝着过早建模模型,同时保持大量的熵以防止局部NA优化。第三,自适应控制。仅当熵量低于阈值时,才会给出熵的熵,设置熵的目标量和动态损失系数,同时减少正常训练轨迹的破坏。最后,为了确保教育培训的稳定性,团队将优化损失的损失。首先,删除损失KL。研究发现,尽管基于高质量的SFT模型,但KL损失仍限制了性能的提高。因此,除了特定阶段外,团队不使用KL对Skywork-O1系列模型的所有公共发行版的损失条款,从而使该模型能够探索和优化理解更完整的能力。其次,令牌级策略的损失。删除了政策损失归一化的归一化时间,损失是在培训批次中平均所有令牌,以提高优化过程的一致性和稳定性。 。 Skywork-O1-7B和Skywork-O1-32B-Preiview一般推理模型仍处于持续改进状态。此开放资源是当前培训过程中最佳性能检查点。可以预期,在两周内,Skywork-O1的官方版本具有更大的功能和更强的推理能力,将被所有人认可,这也是一个完全开放的RE来源。拥抱的脸每月下载超过70,000。自2023年以来,Kunlun Wanwei一直坚持开放资源并在完全拥抱AIGC后促进技术平等。包括代表的代表:2023:开源Skywork-13B系列大型语言模型,具有100亿语言语言水平和600GB的高质量数据集。 2024年:AgentStudio是4000亿个超级模型参数,Skywork-Moe,Skywork-RM/PRM,SkyWork-O1,将是开源数字数字智能R&D Toolkit,AgentStudio,AgentStudio,4000亿MOE SUPER MODE,SKYWORK-MOEE,SKYWORK-MOE,SKYWORK-MOE,SKYWORK-RM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/RM, Skywork-RM/PRM/PRM,Skywork-Skywork-Skywork-Skywork-Skywork-Skywork-Skywork-Skywork-O1参数。今年开放资源的频率已更高。第一季度的开源操作包括:AI短戏剧的模型视频生成Skyreels-V1:每周R1V视觉思维链推理模型的前10个下载:8.75KSkywork-O1新系列:长时间思考的链推理模型。不难知道Kunlun Wanwei开源既全面又彻底,同时考虑了工业需求。一方面,主要布局NIT模型非常全面,占据了AIGC的整个领域,包括Wenshengwen,Wensheng Video,Wensheng Music等。另一方面,这些模型考虑了基础设计中的实际实现需求。提供更高的成本效益并进一步节省计算强度。例如,Skyreels-V1看到了实施场地的前景,模型下载的快速增长也证明了这一市场要求。最重要的是,这些模型是公开采购的,开发人员正在使用中。在拥抱的脸上,Kunlun Wanwei开源模型的下载次数相对较大,上个月的总下载量超过70,000。 △今天的第二次展示,竞争基本的MGA模型变得越来越凶猛,AI的全球领域正在以惊人的速度迭代地出现。几乎每个月都有值得关注的模型,而且这种变化的密度尚未发生。作为中国AIGC轨道上的所有先驱之一,Kunlun Wanwei自2023年以来就建立了全面的切割布局:从主要的大型模型到垂直应用,从技术研发到生态构建。特别值得注意的是,Kunlun Wanwei继续提供开发人员社区工具的高质量模型和链条,而该大学的这种技术概念也提供了独特的竞争。目前,生态系统的开源表现出难以想象的活力。这些开放资源很快是Tuminternet流,制造,医疗保健,教育和其他领域,从而促进了AI技术的大规模实施。在此过程中,ACH探索由Kunlun Wanwei代表的开源从业者的步骤将对AI行业轨迹的发展产生深远的影响。据说,Skywork-OR1的官方版本也将尽快向公众升起并释放。 Skywork开源系列(2025)门户:1。中文推理模型SkyWork-OR1:
对1000亿参数的最强理解模型仅易手。 32B-卷1/20 Deviceek -R1参数;免费商业用途;完全打开源 - 型号的权重,训练集和完整的培训代码,所有开放式起源。这是刚刚发布的Skywork-Or1(开放式推理1)系列模型 - 一般32B尺寸(SkyWork-O1-32B)完全比相同尺寸的Alibaba QWQ-32B多;代码的产生与DeepSeek-R1相当,但成本效益更高。 △SkyWork-OR1-32B-Preiview数学推理:7B和32B都达到了最佳尺寸,而数学专家模型(Skywork-Or1-Math-7B)的性能更为致命。天冈的天空制品也来自AIGC巨头球员Kunlun Wanwei。 Skywork-O1系列模型是完全开放的资源,具有重量的权重,培训数据集和完整的培训代码,所有资源都将上传到GitHub和HuggingFace平台。技术支持博客有蜜蜂n发表在概念平台上,该平台详细说明了数据处理过程,培训方法和基本技术发现,为社区提供了完全实用的实用参考。 The Skywork-Or1 Series Open Source Address: https://github.com/skyworai/skywork-or1 (including models, code, data) Kunlun Wanwei Tiangong Team is more open project resources: https://huggingface.co/Skywork at present, Skywork-or1-7B and Skywork-OR1-32b capabilities are capabilities Still improving.这两个模型的官方版本将在两周内发布,并将启动更多系统和详细的技术报告,以在理解的培训模型中分享经验和PEXERCISE。 3型模型是Skywork-Or1的完全开放资源(开放推理1)开放资源系列中有3种型号:Skywork-Or1-Math-7B:一种专门用于数学领域的特殊模型,并且也有强大的代码功能。 Skywork-O1-7B变化:结合数学考虑到一般和专业精神,及格和代码功能。 Skywork-Or1-32b-Preiview:具有高复杂和更强推理功能的任务的旗舰版本。该团队将Skywork-O1系列的性能与AIE24,AIME25和LiveCodebench进行了比较。 AIE24/25是美国数学邀请赛的基准测试,LiveCodeBench主要评估大语言模型的代码和编程功能的生成。在审查方面,SkyWork-O1系列模型在AVG@K中引入了基本分析的指标,以衡量模型的平均性能,这些模型的平均性能在与K进行尝试时成功解决问题的平均性能仅关注“较少成功”的“对模型的稳定性”,并且更关心模型的稳定性和一般的推理能力,从而提供了一个更全面的模型,并实现了实施模型的实现,从而实现了实现的实现。 Skywork-or1-7b-preiview和Skywork-O1-32b-previews在AIME24和AIME25数据集中的相同参数量表下都达到了最佳性能。 Skywork-O1-32b-preiviews都在LiveCodeBench的LiveCodeBench中实现了最佳功能。通常,Skywork-Or1-32b-preview和DeepSeek-R1之间的差距很小。重要的是要知道,后者的参数量表是前者的20次,这意味着SkyWork-OR1可以带来更好的性能成本。从这个全面的角度来看,SkyWork-O1-32B-Preiview已成为中国对相同规模的认识的最强模型,也是当前支持免费商业用途的当前模型中最强大,最有效的成员之一。此外,Skywork-O1-Math-7b的数学特殊模型是E24/25性能的目标,超出了主7B的当前模型,甚至与Distiled DeepSeek-32B型号(DeepSeek-R1-Disti-Disti-Disti-disti-disti-qwen-32b)接近相同的水平。以下是准确性的曲线AIE24中的模型培训。在AIE24和AIME25中,最终模型分别超过了OpenAi-O3-Mini(低),该模型分别达到了当前SOTA性能大小。同时,这种特殊模型在代码领域也表现出极大的暴力行为(训练后,LiveCodebench从37.6%增加到43.6%)。 △去年11月11月,openai-o3-Mini(低)AIME24标记来自官方网站,Aime25 Mark来自评论网站https://matharen.ai/in,Kunlun Wanwei发布了第一个在中国更复杂的中国模型,在中国,SkyWork-O1,Skywork-Or1系列模型。与OpenAI O1型号的简单复制品不同,Skywork-O1具有内源性功能,例如思考,计划和反思。它包括三种型号,Skywork-O1,Skywork-O1,Kywork-O1-Lite和SkyWork-O1-previews适合各种应用程序,并且可以满足高性能推理中开放资源的不同需求。这Skywork-O1系列在Skywork-O1肩上具有更强的基础,但希望非常强大。它也不能与一系列高级技术的祝福分开。其背后的秘密是:AGI技术有隐藏的漏洞,训练效率提高了50%。 Skywork-O1已进行了其他数据处理更改,培训技术等。首先,就数据而言。为了提高数学功能和模型代码,SkyWork-O1构建了高质量的数学和代码数据集。该团队设计了三个用于数据过滤的标准:经过证实,正确和具有挑战性的和删除的证明问题,这些问题无法自动验证,错误的问题和代码问题,以使单位测试进行。在数学领域总共收集了110,000个问题,主要依靠Numinamath-1.5(包括约896,000个问题),选择了更困难的子集,例如Aime和OlympiaDs,以及诸如DeepScaler,Omni之类的困难问题的资源-Math和Aime 1983-2023增加了。代码字段收集了13.7k,主要基于Leetcode和Taco数据,从而维持完整的测试单元和验证问题,以及向量级别的语义扣除。在“数据过滤器”部分中,团队为每个问题进行了大量抽样,并经过证实的答案,以避免“正确”或“所有错误”的奇观,这些奇观无效,而战略研究无效 - 该模型会产生所有错误,并且无法提供阶层的研究信号; “继续”意味着该模型已完全掌握,并且不断学习的人将浪费计算资源。通过人类的受众群体结合了LLM自动判断的机制,清除了具有模糊语义,不完整信息,不正确格式或包含无关内容的项目。使用LLM-AS-A-Gudge消除1-2K质量失败的数学问题。第二,在强化研究的一部分中,SkyWork-or1使用TRAI的GRPO(相对策略优化)Ning并引入一系列优化技术。在训练过程中,一方面采用了双滤波器方法:离线滤波:使用模型在训练前评估数据,并以0或1的准确率删除样品;在线过滤:每个时期都是在上一个周期中完全掌握的数据的动态删除,以确保模型不断面临着具有挑战性的内容。另一方面,拒绝下降用于进行固定的实时筛选,并且在每个练习步骤中,在当前训练步骤中采样精度为0或1的样品被动态删除。它可以维持政策损失,熵损失和KL损失的合理比率,并防止由于特定重力的非政策损失异常增加而导致的训练不稳定。探索的两个方面主要是在训练管道中进行的。 (1)在多个阶段进行练习:从一个小窗口开始ly增加上下文长度(SEQ_LEN),可以在有限的令牌内促使模型完成活动;然后逐渐扩大窗口大小,并迭代地增加一代的长度,以便模型可以逐步掌握更复杂的长链思维功能。实验证明,多阶段训练可以大大缩短训练时间,同时充分维护模型长度扩展的能力。 。因此,团队研究了两种技术,用于在窗户处理限制下截断样品。 adv-mask之前(在计算优势之前排除截短的样本)和adv-bask(随后添加了Adv-bask)(在计算后与截短样品的好处进行零)。这证明,即使在不阻止截短的样本的情况下,该模型也可以有效地适应并迅速提高性能,并且还证明了多阶段训练框架的稳定性。此外,该模型的勘探能力应保证TICE加强培训。团队进行了探索的三个方面。首先,高温采样。使用τ= 1.0(高于通常的0.6)保持较高的组,这不仅确保足够正确的示例提供研究信号,而且还允许该模型探索更大的解决方案。其次,改善差异 - 内部训练是不同的。通过精细的数据过滤,增加批处理大小并减少数据重复使用,我们将避免从资源的输出方向朝着过早建模模型,同时保持大量的熵以防止局部NA优化。第三,自适应控制。仅当熵量低于阈值时,才会给出熵的熵,设置熵的目标量和动态损失系数,同时减少正常训练轨迹的破坏。最后,为了确保教育培训的稳定性,团队将优化损失的损失。首先,删除损失KL。研究发现,尽管基于高质量的SFT模型,但KL损失仍限制了性能的提高。因此,除了特定阶段外,团队不使用KL对Skywork-O1系列模型的所有公共发行版的损失条款,从而使该模型能够探索和优化理解更完整的能力。其次,令牌级策略的损失。删除了政策损失归一化的归一化时间,损失是在培训批次中平均所有令牌,以提高优化过程的一致性和稳定性。 。 Skywork-O1-7B和Skywork-O1-32B-Preiview一般推理模型仍处于持续改进状态。此开放资源是当前培训过程中最佳性能检查点。可以预期,在两周内,Skywork-O1的官方版本具有更大的功能和更强的推理能力,将被所有人认可,这也是一个完全开放的RE来源。拥抱的脸每月下载超过70,000。自2023年以来,Kunlun Wanwei一直坚持开放资源并在完全拥抱AIGC后促进技术平等。包括代表的代表:2023:开源Skywork-13B系列大型语言模型,具有100亿语言语言水平和600GB的高质量数据集。 2024年:AgentStudio是4000亿个超级模型参数,Skywork-Moe,Skywork-RM/PRM,SkyWork-O1,将是开源数字数字智能R&D Toolkit,AgentStudio,AgentStudio,4000亿MOE SUPER MODE,SKYWORK-MOEE,SKYWORK-MOE,SKYWORK-MOE,SKYWORK-RM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/PRM/RM, Skywork-RM/PRM/PRM,Skywork-Skywork-Skywork-Skywork-Skywork-Skywork-Skywork-Skywork-O1参数。今年开放资源的频率已更高。第一季度的开源操作包括:AI短戏剧的模型视频生成Skyreels-V1:每周R1V视觉思维链推理模型的前10个下载:8.75KSkywork-O1新系列:长时间思考的链推理模型。不难知道Kunlun Wanwei开源既全面又彻底,同时考虑了工业需求。一方面,主要布局NIT模型非常全面,占据了AIGC的整个领域,包括Wenshengwen,Wensheng Video,Wensheng Music等。另一方面,这些模型考虑了基础设计中的实际实现需求。提供更高的成本效益并进一步节省计算强度。例如,Skyreels-V1看到了实施场地的前景,模型下载的快速增长也证明了这一市场要求。最重要的是,这些模型是公开采购的,开发人员正在使用中。在拥抱的脸上,Kunlun Wanwei开源模型的下载次数相对较大,上个月的总下载量超过70,000。 △今天的第二次展示,竞争基本的MGA模型变得越来越凶猛,AI的全球领域正在以惊人的速度迭代地出现。几乎每个月都有值得关注的模型,而且这种变化的密度尚未发生。作为中国AIGC轨道上的所有先驱之一,Kunlun Wanwei自2023年以来就建立了全面的切割布局:从主要的大型模型到垂直应用,从技术研发到生态构建。特别值得注意的是,Kunlun Wanwei继续提供开发人员社区工具的高质量模型和链条,而该大学的这种技术概念也提供了独特的竞争。目前,生态系统的开源表现出难以想象的活力。这些开放资源很快是Tuminternet流,制造,医疗保健,教育和其他领域,从而促进了AI技术的大规模实施。在此过程中,ACH探索由Kunlun Wanwei代表的开源从业者的步骤将对AI行业轨迹的发展产生深远的影响。据说,Skywork-OR1的官方版本也将尽快向公众升起并释放。 Skywork开源系列(2025)门户:1。中文推理模型SkyWork-OR1: 下一篇:没有了
